Elixir Under Uncertainty: Mechanics-Grounded Risk-Sensitive Control for Clash Royale
Luke Blommesteyn
Mechanics-grounded risk control for Clash Royale. Using only the official rules and card catalogue, we frame elixir trading as risk-sensitive decision-making under partial observability and prove structural results that turn into coaching-ready heuristics.
The story: the seven-elixir freeze
Double elixir, forty seconds on the clock. You’re up a tower. You’re sitting at seven elixir and your opponent just slammed a five-cost into the other lane. Push now while they’re tapped out, or hold and protect the lead? Every Clash Royale player has felt that exact half-second of paralysis — and most of us resolve it on vibes.
Here’s the thing: you know more than it feels like. They spent five, so right now they have at most five. The clock phase fixes how fast that refills. You’re ahead, so a blown push costs you more than a good one wins. None of that requires reading their hand or mining a million ladder replays — it falls straight out of the game’s own rules.
This note takes that freeze and turns it into something you can compute. It frames elixir trading as risk-sensitive decision-making under partial observability, using only the official mechanics and card catalogue as data, and shows that the gut heuristics — bank when ahead, take variance when behind, probe when it’s cheap — are the mathematically right shape. The payoff is a go/no-go threshold you can carry onto ladder, not a black box.
Abstract
We present a mechanics-grounded framework for elixir trading in Clash Royale. Using only the game's rules (elixir regeneration, deck cycle, timing) and the card catalogue (costs, base stats) as data, we cast decision-making as risk-sensitive partial observability over the opponent's elixir, hand rotation, and archetype. We derive structural results—potential-based shaping invariance, elixir belief bounds after plays, scoreline/clock-aware risk thresholds, lane decoupling via shadow prices, value-of-information guarantees, belief-compression error bounds, and delay robustness—and specify algorithms that exploit them. We also define mechanics-consistent testbeds that benchmark policies without relying on large-scale ladder logs. The result is a data-light, actionable approach to risk-aware control in real-time card battlers.
Brief Summary
This note is laid out so you can read along: skim the TL;DR, then glance at each theorem and its callout box while you play or watch a set.
Goal. Make smarter elixir decisions when you don't fully know what your opponent has or how much elixir they banked.
How. We turn Clash Royale into a small decision model that respects real mechanics (regen speed, 10-cap, 8-card deck, 4-card hand). We add a risk dial that tightens play when you're ahead and loosens it when you're behind.
Why it helps. You get simple rules of thumb: when to hold vs push, how to split spend across lanes, and when a cheap "probe" is worth it to learn your opponent's hand/elixir.
- Thresholds: For each situation, there's a minimum safe elixir to start a push; this threshold rises if you're protecting a lead.
- Shadow price: Treat elixir like a budget with a price; this balances left/right lane spending automatically.
- Smart info: Quick, cheap plays that reveal hand or elixir are often worth it if they unlock a better push later.
- Robustness: The rules still work with small delays or compressed estimates of the opponent's state.
Quick Start for Players & Coaches
- If you're ahead late: Raise the risk threshold \(\kappa^\star\), bank elixir, and force them to make the first expensive move.
- If you're behind: Lower \(\kappa^\star\); lean into variance and use probes to surface the counter that unlocks your win condition.
- Two lanes: Spend where marginal tower damage per elixir beats the shadow price \(\mu\); split when both lanes price out evenly.
- Track reveals: Update the elixir envelopes and hand belief after every play; the tighter the belief, the harder you can commit.
Opponent plays a 5-cost card. They must have had \(\ge 5\) before the play; immediately after, they're between 0 and 5 (before regen). In double elixir, they'll regen faster, but they can't exceed the 10-cap. If you're ahead at 0:40, raise the threshold: wait until you're sure they can't full-counter your win-con cheaply. If you're behind, a 2–3 elixir "probe" (e.g., a cheap cycle or bait at bridge) might be worth it to reveal the counter and open a timing window.
Game-Theory Lens
Tempo as currency. Think of elixir as a priced resource with a floating shadow price \(\mu\); every push you consider should beat that internal price on value-per-elixir.
Probes as bets. Cheap plays buy information. Greedy VOI says you stop probing when the marginal intel no longer beats the elixir you could swing elsewhere.
Thresholds as stop-losses. The Topkis threshold \(\kappa^\star\) is your go/no-go bar. Ahead? Raise it and force the opponent to spend first. Behind? Drop it and take variance.
Beliefs stay light. Compress the opponent state to envelopes + archetype logits; the Lipschitz bound guarantees you do not need perfect tracking to make good calls.
Math & ML TL;DR
Model. Risk-sensitive POMDP with state \(s_t = (x_t, z_t)\), hidden opponent elixir/hand \(z_t\), observations \(o_t\), and controls that choose hold or play (c, \ell).
Objective. Optimise \(\mathbb{E}[R] - \lambda\,\mathrm{Var}(R)\), \(\mathrm{CVaR}_\alpha(R)\), or min-max robust return with scoreline-aware risk \(\lambda_t\).
Structure. Topkis thresholds for go/hold, shadow-price dual for lanes, adaptive-submodular VOI for probes, Lipschitz bounds for belief compression.
Implementation. Belief features combine regen envelopes with archetype logits feeding a QMDP-style policy and learnable risk dial.
Introduction
Competitive Clash Royale hinges on trading elixir for tempo, value, and tower damage while partially observing the opponent's state. Strong players implicitly maintain beliefs about opponent elixir, hand cycle, and archetype, adjusting aggression by clock phase and scoreline (protecting a lead vs. chasing).
We encode that reasoning in a mechanics-grounded control framework that: (i) formalizes the game as a risk-sensitive POMDP; (ii) proves decision-structure properties (thresholds, decouplings, and information value); (iii) prescribes algorithms that run on compact belief features; and (iv) evaluates on mechanics-consistent, data-light testbeds.
Contributions
- Mechanics-grounded formulation: POMDP with elixir regen, cycle, and partial observability over opponent elixir/hand/archetype.
- Structural results: shaping invariance; elixir belief bounds after plays; risk-threshold monotonicity; lane decoupling via a shadow price; greedy VOI guarantees; belief-compression regret; delay robustness.
- Algorithms: belief-augmented policy with a risk dial; shadow-price control; greedy probing for information.
- Testbeds: mechanics-consistent, data-light benchmarks (closed-form or tiny DPs) for reproducible evaluation without large logs.
What data do we use?
Only official mechanics and catalogue parameters: elixir regeneration schedule (normal/double/triple), 10-elixir cap, the 8-card deck with a 4-card FIFO hand, and card costs/base stats (HP, DPS, range, speed). We do not rely on large-scale match logs; external telemetry is future work for validation.
Glossary (fast definitions)
| Risk dial | A number that makes you more conservative when winning and more aggressive when losing. |
|---|---|
| Shadow price | A "price per elixir" that balances where to spend (left vs. right lane). |
| Probe | A cheap play that reveals opponent information (hand/elixir) to set up a better push. |
| Belief | Your internal estimate of their elixir/hand/archetype, updated from what you observe. |
Mechanics & Assumptions
We study decision times \(t = 0,1,\dots\) with actions of "play a legal card at a placement" or "wait." Between decisions, physics evolves deterministically at the macro level and elixir regenerates.
Assumptions
- Elixir process. Each player has elixir \(e_t \in [0,10]\). The regeneration rate \(g_t\) is piecewise constant by clock phase (normal/double/triple).
- Cycle. Hand is a size-4 FIFO sample from an 8-card deck; after playing a card, it moves to the back and a new card is drawn immediately.
- Observations. We observe public board state and opponent plays with costs; opponent elixir \(e^O_t\), hand \(\mathcal{H}^O_t\), and archetype \(a\) are hidden.
- Rewards. Per-step reward aggregates crown/tower HP change and tempo; a potential term may reattribute credit to elixir trades.
- Legalities. Placement legality and hand constraints are respected; actions with cost \(> e_t\) are infeasible.
Plain English. We only assume the real game rules: how fast elixir comes back, the 10-cap, and how decks/hand cycling works. We can reason about the opponent without seeing their hand.
Formal Model
Let \(\mathcal{M} = (\mathcal{S}, \mathcal{A}, \mathcal{O}, T, \Omega, R, \gamma)\) be a POMDP with state \(s_t = (x_t, z_t)\), public component \(x_t\) (board, clock, your elixir/hand), hidden component \(z_t = (e^O_t, \mathcal{H}^O_t, a)\), observation \(o_t = f(x_t)\). The action \(u_t \in \mathcal{A}\) is either \emph{hold} or \emph{play} \((c, \ell)\) for a legal card \(c\) and placement \(\ell\). The transition couples (i) elixir updates \(e_{t+1} = \min\{10, e_t - \mathrm{cost}(u_t) + g_t\}\); (ii) cycle updates; (iii) board evolution.
Risk-sensitive criteria
We consider:
\[J_{\lambda}(\pi) = \mathbb{E}[R] - \lambda \, \mathrm{Var}(R),\qquad \max \; \mathrm{CVaR}_{\alpha}(R) = \max\, \mathbb{E}[R] - \lambda\, \rho_{\alpha}(R),\qquad \sup_{\pi} \inf_{\delta \in \mathcal{D}} \mathbb{E}_{\delta}[R].\]
We use a scoreline/clock-aware risk parameter \(\lambda_t = \lambda(\text{lead}, \text{clock})\).
Structural Results
This project sits at the line between control math and Clash Royale game feel. The math gives you guarantees; the game theory perspective tells you what to do with them mid-match. Read each result as: formal statement + a plain-language note you can apply on ladder.
Potential-based shaping invariance on beliefs
Theorem. Let the belief-MDP state be \((x_t, b_t)\) with belief \(b_t\) over \(z_t\). For any potential \(\Phi\), define \(r'_t = r_t + \gamma \Phi(x_{t+1}, b_{t+1}) - \Phi(x_t, b_t)\). A policy is optimal under \(r\) iff it is optimal under \(r'\).
Plain English. Read-along cue. Re-scaling rewards by moving points between steps (without changing totals) doesn't change which choices are best. We can make credit assignment cleaner without changing optimal play.
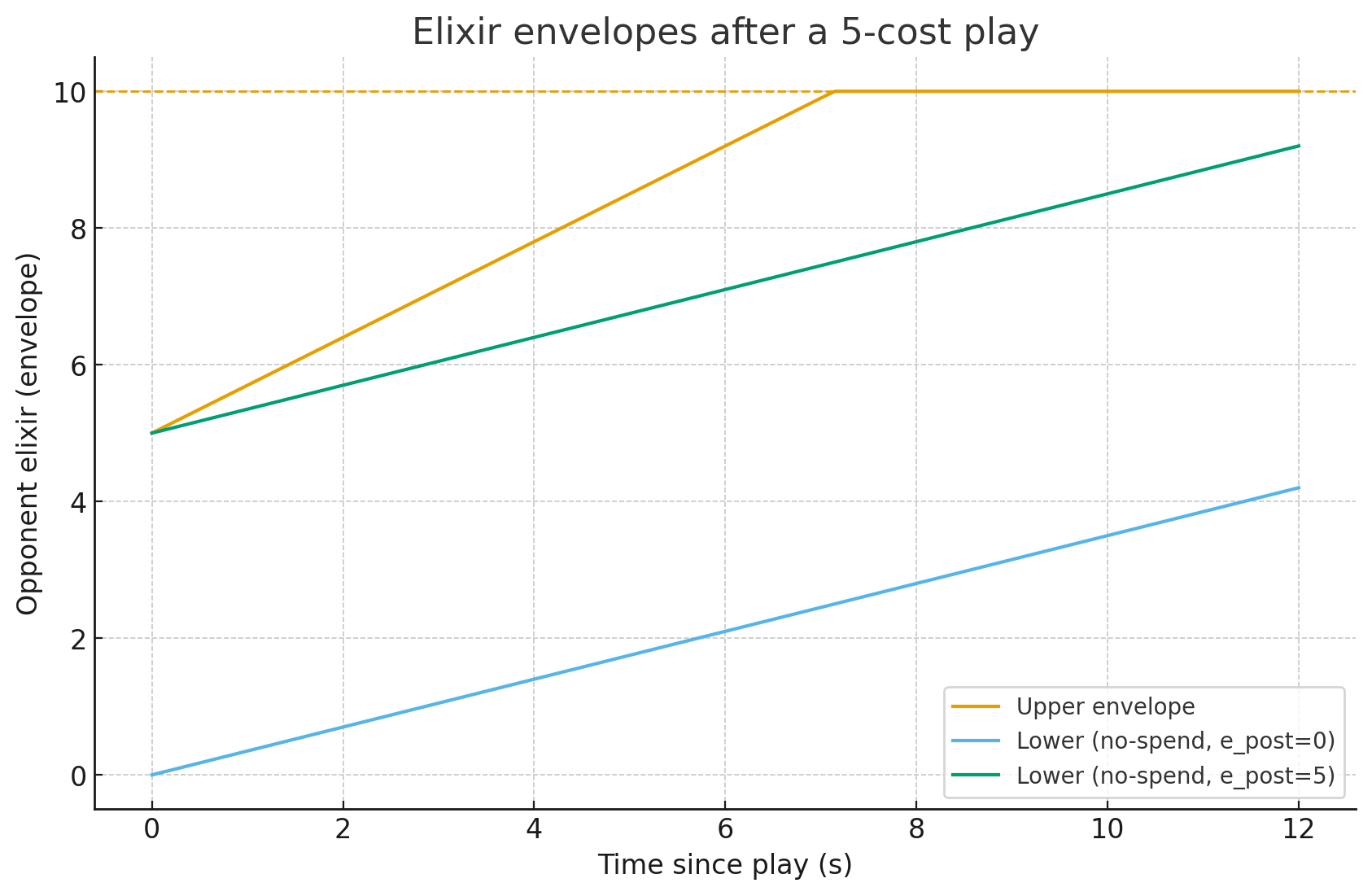
Elixir belief support after an observed play
Theorem. Opponent plays a card of cost \(c\). Legality implies \(e^O_{t^-} \ge c\) and the post-play elixir satisfies \(e^O_{t^+} = e^O_{t^-} - c \in [0, 10-c]\). Regen on \((t, t+\tau]\) with rate in \([g_{\min}, g_{\max}]\) yields envelopes for \(e^O_{t+\tau}\).
Plain English. Read-along cue. Right after they drop a 5-cost, they have at most 5 left. As time passes, their elixir climbs but never past 10. Track "how broke can they be" vs "what's the most they could have by now."
Corollary: Tick-wise envelopes
With decision tick \(\Delta t\), \(k\) steps after the play: \(0 \le e^O_{t+k} \le \min\{10, (10-c) + k g_{\max} \Delta t\}\). Tighten the lower bound if they do not spend again.
Risk-threshold monotonicity
Theorem. Order actions \(\texttt{hold} \preceq \texttt{play}\) and let \(\kappa\) be a scalar risk index. If \(Q\) has increasing differences in \((\kappa, a)\), there exists a threshold \(\kappa^{\star}(b)\): play when \(\kappa \le \kappa^{\star}(b)\), hold otherwise.
Plain English. Read-along cue. Draw a line: above it, you wait; below it, you go. That line moves with score and clock—more conservative when ahead, looser when behind.
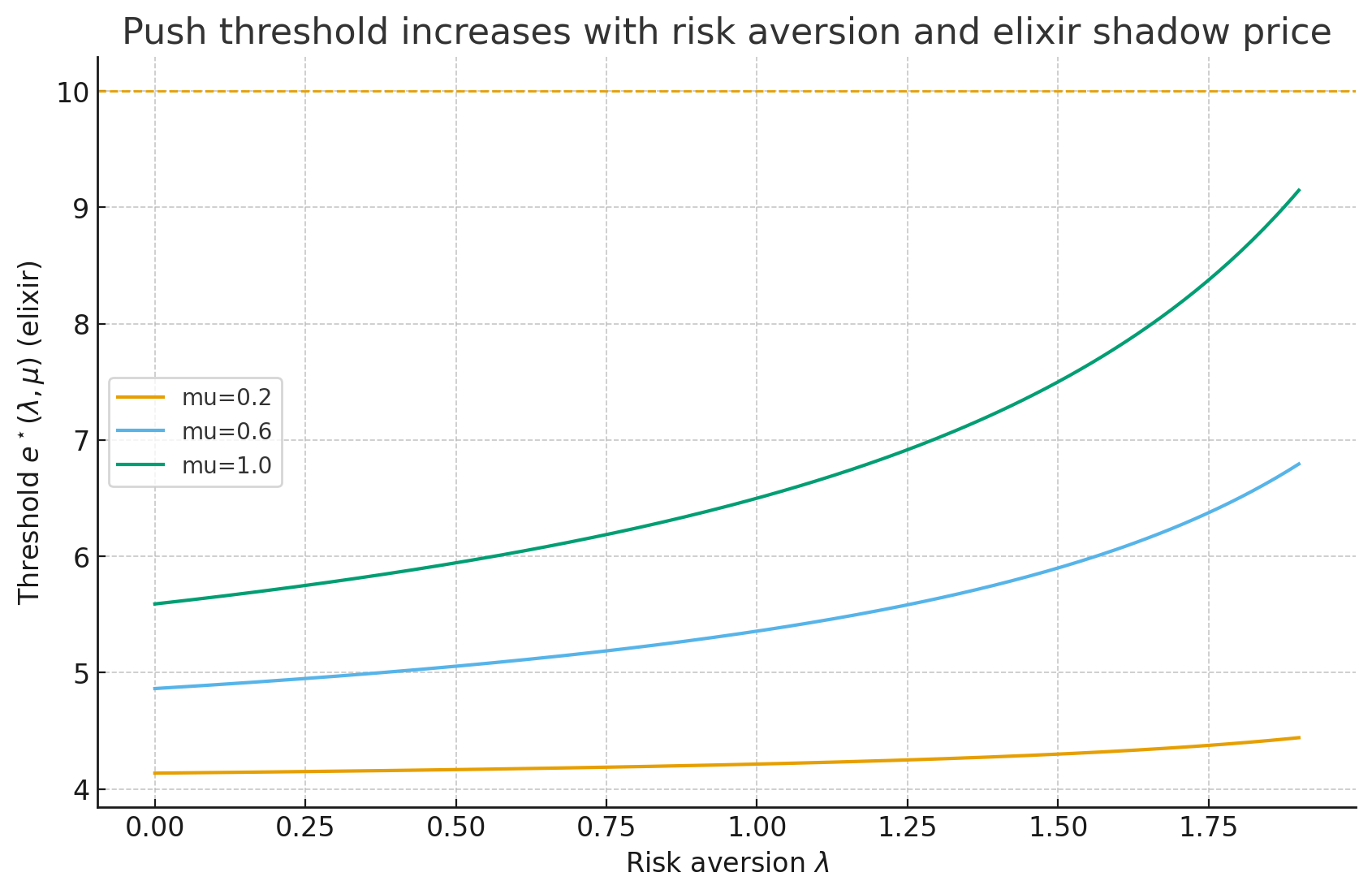
Risk-aware push threshold
Proposition. For a push costing \(c\) with \(\mathbb{E}[R] = \alpha(e-c)+\beta\) and \(\mathrm{Var}(R) = \sigma^2(e-c)\), and elixir shadow price \(\mu\), if \(\alpha > \lambda \sigma^2\) then push iff \(e \ge e^{\star}(\lambda, \mu) = c + \frac{\mu c - \beta}{\alpha - \lambda \sigma^2}\).
Plain English. Read-along cue. The minimum elixir you want before pushing goes up when you're protecting a lead (higher risk aversion) or when elixir is extra valuable elsewhere (higher shadow price).
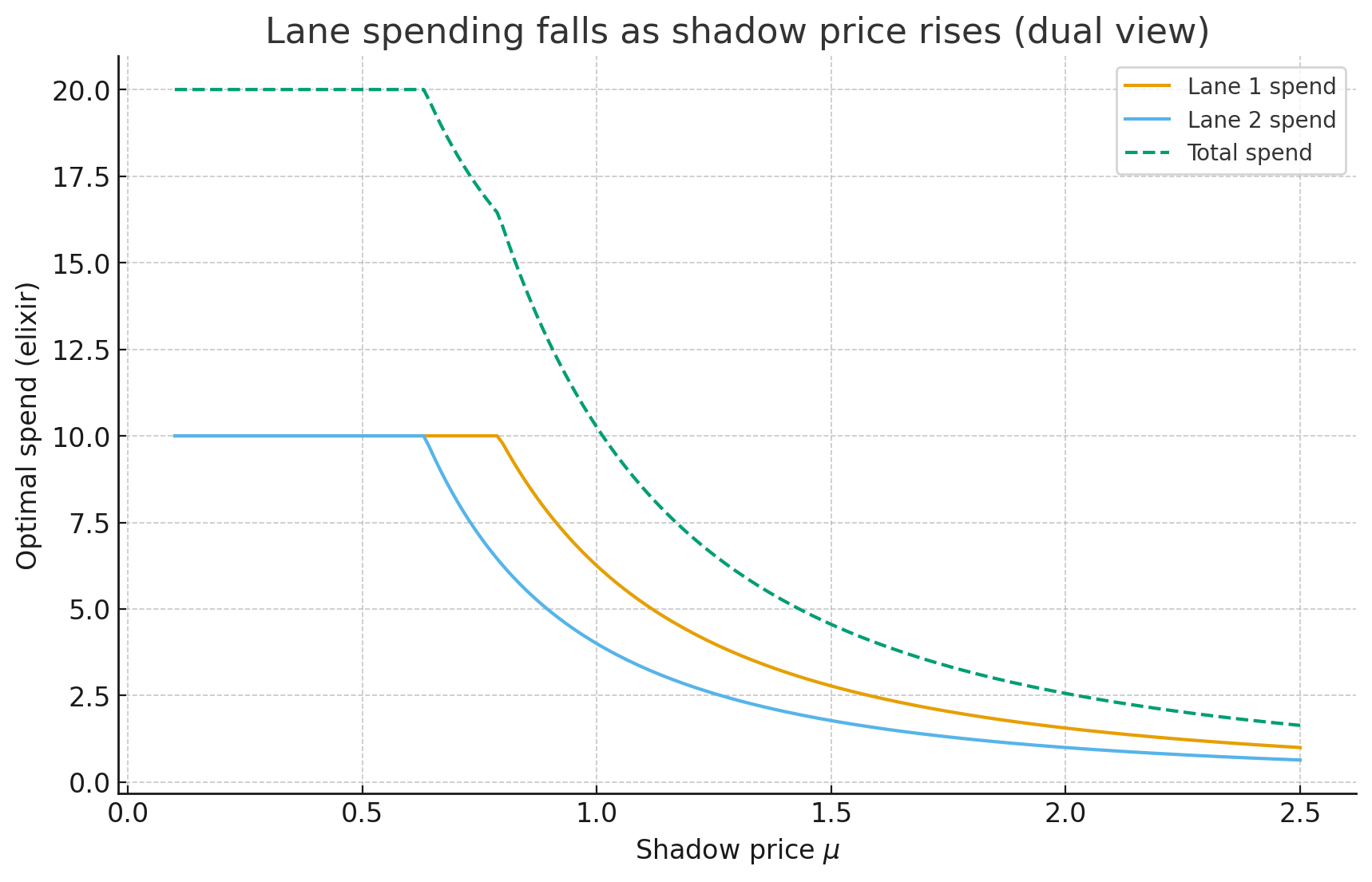
Shadow-price decoupling across lanes
Theorem. Relax the shared elixir budget with price \(\mu\); solve each lane separately with a per-elixir penalty. Bisection on \(\mu\) balances lanes and gives a dual upper bound.
Plain English. Read-along cue. Pretend each elixir "costs" \(\mu\). Spend where it delivers the most return per coin and adjust \(\mu\) until your spend fits the total budget.
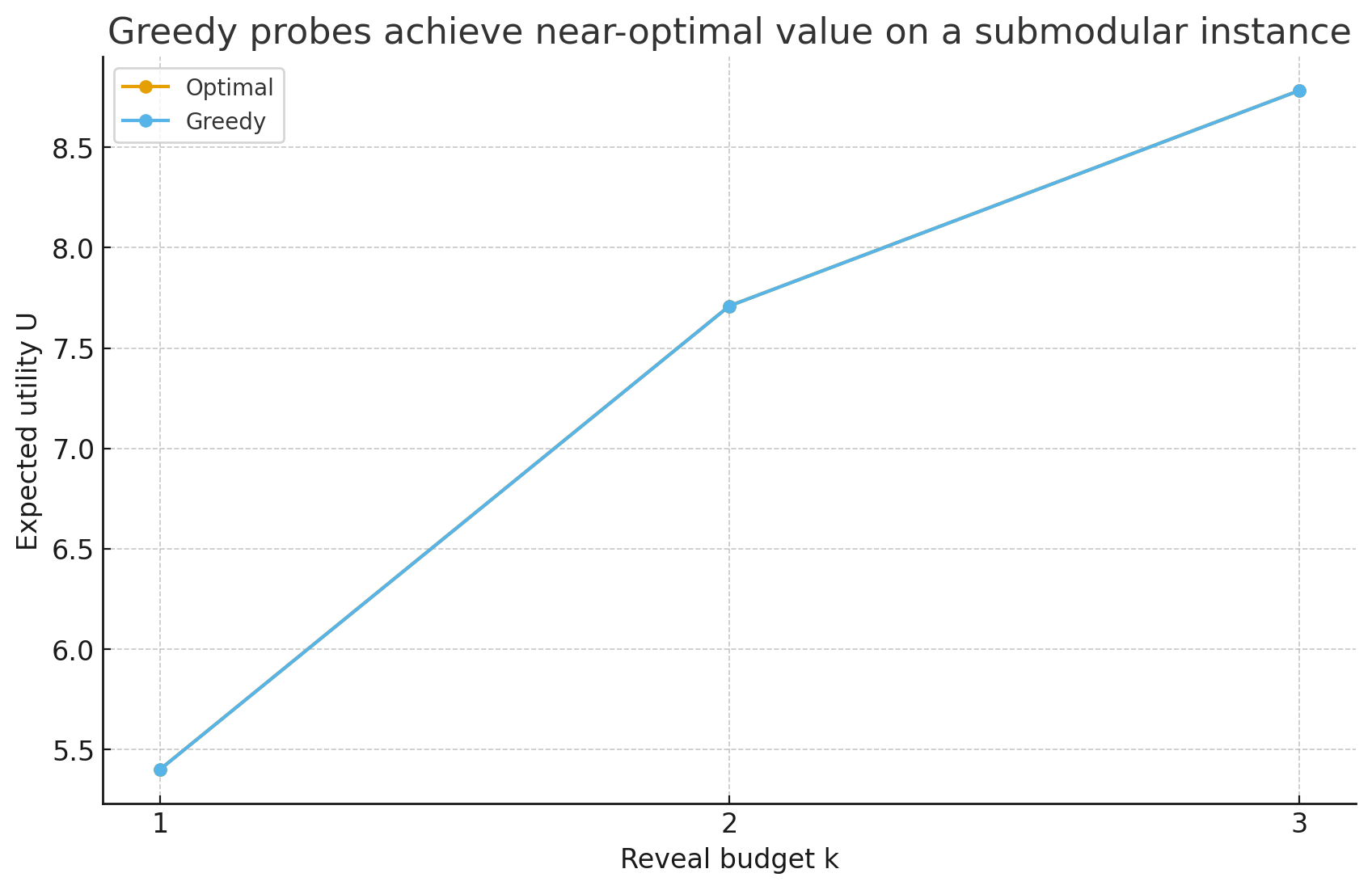
Greedy VOI under adaptive submodularity
Theorem. If expected return \(U\) is monotone and adaptively submodular in reveals, the greedy "max \(\Delta U\) per time" probe is a \((1-1/e)\)-approximation to the optimal \(k\)-reveal policy.
Plain English. Read-along cue. Small, fast info plays that reveal hand/elixir are provably near-optimal when chosen greedily.
Belief compression regret
Theorem. If \(Q\) is Lipschitz in belief and the compressed belief has uniform error \(\epsilon\), then \(|J(\pi_{\phi}) - J(\pi_{\star})| \le \frac{2 \gamma L}{(1-\gamma)^2} \, \epsilon\).
Plain English. Read-along cue. Rough estimates of the opponent (compressed beliefs) are fine: performance drops smoothly with estimation error.
Delay robustness
Theorem. With Lipschitz dynamics/rewards and latency \(\Delta \in [0, \delta]\), \(J(\pi_{\text{delay}}) \ge J(\pi) - O(L\delta)\).
Plain English. Read-along cue. A bit of input lag won't break the policy; losses scale proportionally with the delay.
Algorithms (provable or bounded)
Belief-Augmented Policy (BAP). Policy over compressed beliefs \(\phi(b_t)\) with a risk dial \(\lambda_t\). Use QMDP or one-step look-ahead; the belief compression theorem bounds suboptimality.
Shadow-price control. Tune \(\mu\) online (dual ascent) to balance lanes.
Risk schedule. Precompute \(\kappa^{\star}(\text{lead}, \text{clock})\) from tiny MDPs.
Greedy probing. Choose micro-plays with maximal \(\Delta \mathrm{CVaR}/\Delta t\) or \(\Delta U/\Delta t\) with safety guarantees.
Belief-Augmented Policy with Risk Dial (sketch)
Initialize policy π_θ, belief filter B, risk schedule λ_t
for each decision time t:
b_t ← B(history)
φ_t ← φ(b_t)
κ_t ← κ(lead, clock) # risk index
choose u_t ∈ argmax_u Q^risk(o_t, φ_t, u; κ_t)
execute u_t, observe outcome, update BMechanics-Consistent Testbeds (data-light)
- Elixir bank vs. push: two actions {hold, push} with stochastic opponent counter; yields explicit thresholds.
- Two-lane knapsack: independent per-lane values with shared elixir; compare primal (shadow price) to the dual bound.
- Reveal game: micro-plays reveal a card or tighten a lower bound on \(e^O\); compare greedy probing to the optimal \(k\)-reveal policy.
Notation
| Symbol | Meaning |
|---|---|
| \(e_t, e^O_t\) | Your / opponent elixir at time \(t\) |
| \(g_t\) | Elixir regeneration rate (by clock phase) |
| \(c\) | Card elixir cost; \(e^{\star}\) threshold from the push proposition |
| \(\mathcal{H}^O_t\) | Opponent hand (hidden) at time \(t\) |
| \(a\) | Opponent archetype (hidden) |
| \(\lambda, \kappa\) | Risk aversion and risk index (lead/clock) |
| \(\mu\) | Shadow price of elixir (dual variable) |
| \(R\) | Return random variable; \(\mathrm{CVaR}_{\alpha}\) tail risk measure |
| \(\phi(b)\) | Compressed belief features |
| \(t^{-}, t^{+}\) | Left/right limits around a play instant |
FAQ (Coach / Player)
- I don't know their exact elixir—can I still use this?
- Yes. Use the envelopes from the elixir-bounds theorem and tighten them after each reveal.
- When is a cheap probe worth it?
- If it narrows their hand/elixir and unlocks your win-con timing, greedy probes are near-optimal.
- How do I split lanes?
- Spend where the value per elixir is highest given \(\mu\); adjust until total spend fits the budget.
- I'm ahead with 45 seconds left.
- Turn the risk dial up: wait for better trades and require a higher threshold \(e^{\star}\) before pushing.
Discussion & Limitations
Our assumptions target macro elixir/cycle economics; we do not claim pixel-level fidelity. Structural results are robust to simulator details, but numerical curves depend on stylized parameters. Extending to POSGs (explicit opponent models) is straightforward; the belief-MDP approach carries over. We do not rely on large-scale ladder logs; validating on real telemetry is future work.
Ethics. This work concerns analysis and training aids; it is not intended for automation in live ladder play.
Conclusion
A mechanics-grounded path to elixir trading yields policy structure (thresholds), coupling relaxations (shadow prices), and information-theoretic guidance under risk—all with data-light inputs (rules and catalogue). This supports reproducible research and coaching tools for real-time card battlers.
Reproducibility Checklist
- Seeds and exact parameters for toy instances.
- Closed-form thresholds and small DP scripts for testbeds.
- Specification of the \(\lambda_t\) schedule and belief compression features.
Appendix (sketches)
Belief-MDP & shaping
Beliefs \(b_t\) over hidden state yield an MDP with state \((x_t, b_t)\). Shaped returns differ by a potential term; value functions shift by a constant, preserving optimal policies.
Risk-threshold monotonicity
With increasing differences in \((\kappa, a)\) and diminishing returns in elixir, the argmax set is non-decreasing in \(\kappa\); a threshold exists. Mean–variance and CVaR surrogates satisfy this.
Value of information
If expected return is adaptively submodular in reveals, greedy selection achieves \((1-1/e)\) of optimal for a reveal budget.
Belief compression
Lipschitz continuity plus the performance-difference lemma yields \(|J(\pi_{\phi})-J(\pi_{\star})| \le \tfrac{2\gamma L}{(1-\gamma)^2} \, \epsilon\).
Delay robustness
Model latency as adversarial timing within \([0,\delta]\). Value loss is \(O(L\delta)\) per step; geometric discounting gives the bound.